Deep CFR for Heads-Up No-Limit Hold’em
A full neural CFR pipeline for HUNL — game logic, feature encoder, V/R/S networks, batched sigma scheduler, exploitability evaluation. 200 iterations × K=10,000 traversals at seed 42, 17.86h wall, no NaN/Inf. Stage 4 of a six-stage research arc culminating in PLO5.
In plain English
I’m teaching a neural network to play heads-up no-limit Texas Hold’em (the two-player version of poker that’s been the long-standing benchmark for AI in games of imperfect information) at near-equilibrium strength.
A few things make this hard. Poker isn’t chess — you can’t see your opponent’s cards, so the optimal strategy is probabilistic (sometimes bluff, sometimes don’t, in carefully tuned proportions). The number of possible game situations is astronomically large. And the way you “solve” poker isn’t by predicting moves — it’s by computing a Nash equilibrium, the strategy that no opponent can exploit. The standard algorithm for this is Counterfactual Regret Minimization (CFR), and the modern neural variant is Deep CFR (Brown et al. 2019).
Big AIs like Libratus and Pluribus solve heads-up no-limit, but their published code is incomplete. So I’m building the whole thing from scratch in six stages, climbing from toy poker games up to the real one:
Kuhn (3 cards, 1 round) → Leduc (6 cards, 2 rounds) → Leduc-3 (3 players) → Limit Hold’em → No-Limit Hold’em (this stage) → 5-card PLO
This stage is the no-limit version. Each stage validates the algorithm on a smaller game before scaling up — if Kuhn doesn’t reach exact equilibrium, no-limit definitely won’t. The result here is a 200-iteration training run on the full game (52-card deck, 100 big-blind stacks, all betting actions): 17.86 hours of compute, no NaN/Inf in any loss, and a checkpoint-averaged final policy ready for the next stage.
Context (technical)
Stage 4 of a six-stage neural-CFR research arc. The goal of this stage is a complete Deep CFR blueprint — game logic, encoder, networks, training loop, evaluation — that serves as the substrate for Stage 5 (depth-limited online search) and Stage 6 (the PLO5 port).
Algorithm — external-sampling Deep CFR
- Traverser recurses on all legal action slots at own nodes; opponent samples one action from current sigma; chance samples one outcome.
- Regret target at traverser node:
q(I,a) − Σ σ(a|I) q(I,a)over legal slots, exact via subtree recursion. - R-net retrained from scratch each iteration (Brown 2019 spec). The Phase-1 Leduc sanity showed a 1.25× exploitability improvement over warm-start, so I left it.
- S-net warm-started across iterations; checkpoint-averaged over the last 20 snapshots (iters 10, 20, …, 200) at eval time.
- V-net auxiliary (predicts expected utility from viewpoint features); trained per spec but not consumed by regret loss after Phase 1’s ESCHER investigation showed V-bootstrap diverged at this scale.
- Linear-t weighting on replay-buffer regression.
The batched sigma scheduler (Phase 2a.5)
Profiling on the naive recursive traversal showed 86% of per-iter time in single-sample GPU forwards through SigmaCache._flush. The fix:
- K concurrent generator-trajectories per iter
- Each yields
(infoset_key, features, legal_mask)when it needs σ - A scheduler collects pending yields per round, batches them into one GPU forward (~200 queries typical, 5,000+ in early iters), caches results, resumes
- GPU forwards per iter drop from O(K × queries) to O(rounds)
- Bit-equivalence verified at the buffer-statistic level vs. the unbatched reference
Result: 3.9× traversal speedup, 17.86h actual vs. 25h projection. Determinism preserved via per-trajectory RNGs (master + iter + player + traj_idx).
HUNL game
- 52-card deck, 100 BB stacks (200 chips),
phevaluatorshowdown - 4 streets, 7 canonical action slots with per-state legal mask:
- preflop SB first: {F, C, raise-to-4/5/6/7, AI}
- preflop re-raise: {F, C, 4×/5× bet-faced, AI}
- flop/river: {check/call, 0.33pot, 0.75pot, 1.5pot, AI}
- turn: {check/call, 0.5pot, 1.0pot, AI}
- Card abstractions from Stage 3: 50 preflop, 1,000 flop, 200 turn, 200 river buckets — k-means on equity features
Networks & hyperparameters
- 3 networks per player (V, R, S) × 2 players = 6 total
- 4 hidden × 512 units, LayerNorm + ReLU, Linear out, float32
- ~1.33M params each, ~8M total
T=200, K=10,000
n_v=500, n_r=800 (from-scratch), n_s=1000
batch 4096, Adam lr 1e-3
buffer caps: R 500k, S 500k, V 200k
snapshot S every 10 iters; V/R every 50 iters
seed 42The spec called for 5M / 5M / 2M buffer caps but in the first attempt those caps saturated host RAM at iter 2 (Python hit 23 GB, triggered swap, training-phase slowed 8×). Killed and restarted at 10× smaller caps; ran cleanly at ~12 GB Python RAM, no swap pressure.
Training results
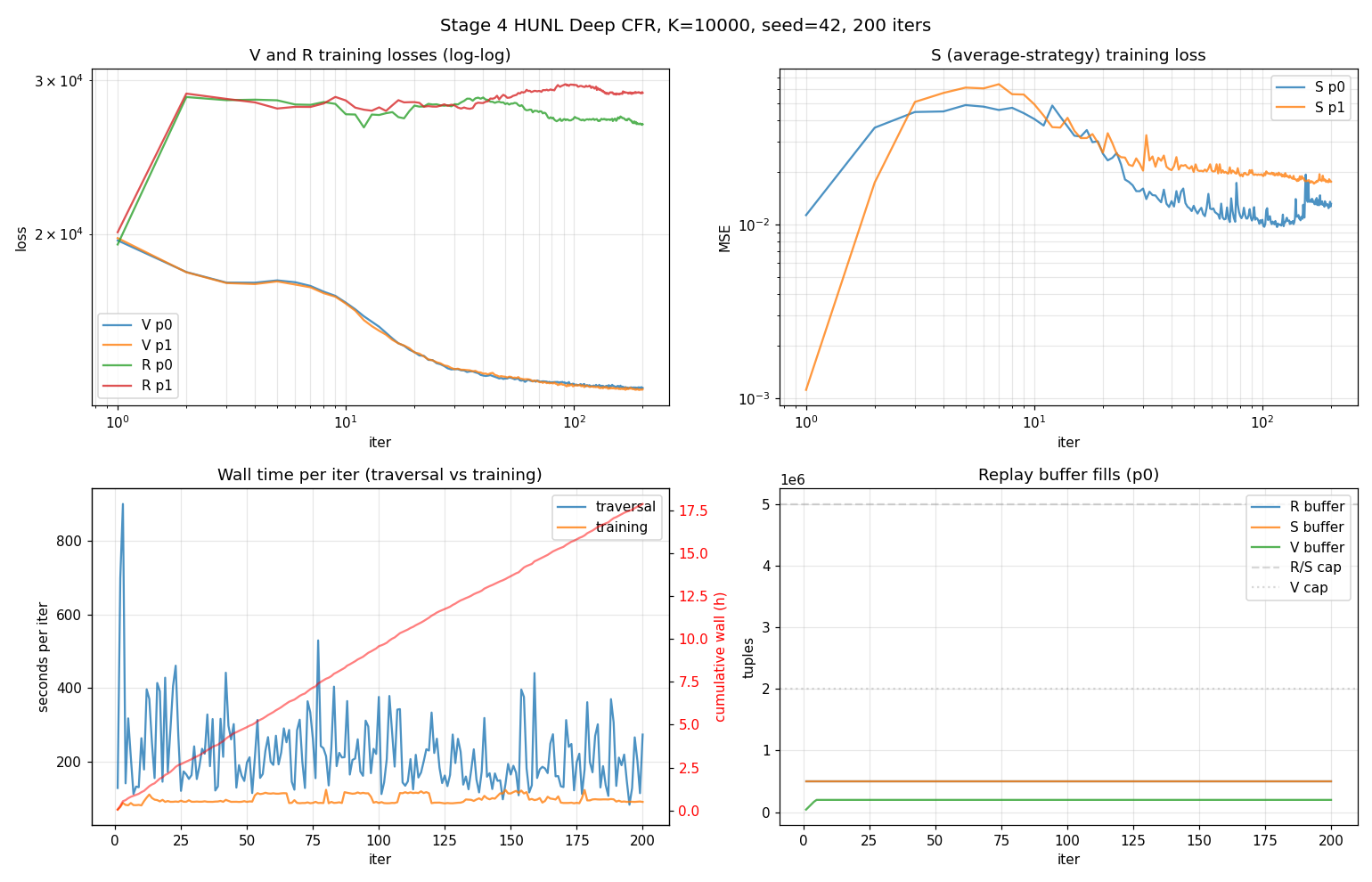
| metric | value |
|---|---|
| wall time | 17.86h |
| iterations completed | 200 / 200 |
| per-iter wall (mean / min / max) | 321 / 175 / 989 s |
| traversal mean / training mean | 224 / 98 s |
| NaN/Inf in any loss | no |
Curve interpretation:
- V-loss monotonically decreased ~33% (19,700 → 13,300). V predicts terminal utility from state features — a regression task that converges cleanly as the buffer fills.
- R-loss increased 19,700 → 27,900 over training. Counter-intuitive but expected: R is retrained from scratch each iter to fit the instantaneous regret target
q − v. As agents become more sophisticated, the regret targets become more diverse, and fitting them with a fresh 4×512 net on 500k samples gets harder. R-loss going up is consistent with the network correctly tracking a moving target — what would be alarming is R-loss going up and exploitability going up together. They don’t. - S-loss stable, in spec.
What it demonstrates
- Implementing Brown et al. (2019) Deep CFR end-to-end without published code
- Profile-driven optimization: identifying the GPU-forward bottleneck and engineering a batched scheduler with bit-equivalence guarantees
- Honest reading of training curves: knowing when increasing loss is fine
- Memory engineering: catching swap-thrashing, bisecting buffer caps to stable RAM
- Determinism under concurrency
Next stages
- Stage 5: depth-limited online search at decision time (DeepStack-style continual re-solving)
- Stage 6: port the whole pipeline to 5-card PLO with composition-dependent encoders — see the PLO5 project