
Targeting users by uplift
beats targeting by risk.
Subscription-churn pipeline on 6.8M KKBox members. The R-learner net-value curve sits $1,174 above the risk-targeting baseline at a fixed 20% retention budget — a +92% lift in dollars retained.
Read the writeup- R-learner
- X-learner
- T-learner
- Risk (GBM)
- Random
I like problems where the data is messy, the answer isn't obvious, and you have to actually measure whether what you built works. Outside of code I play pickleball, snowboard, and play NLH and PLO.
Selected work
See all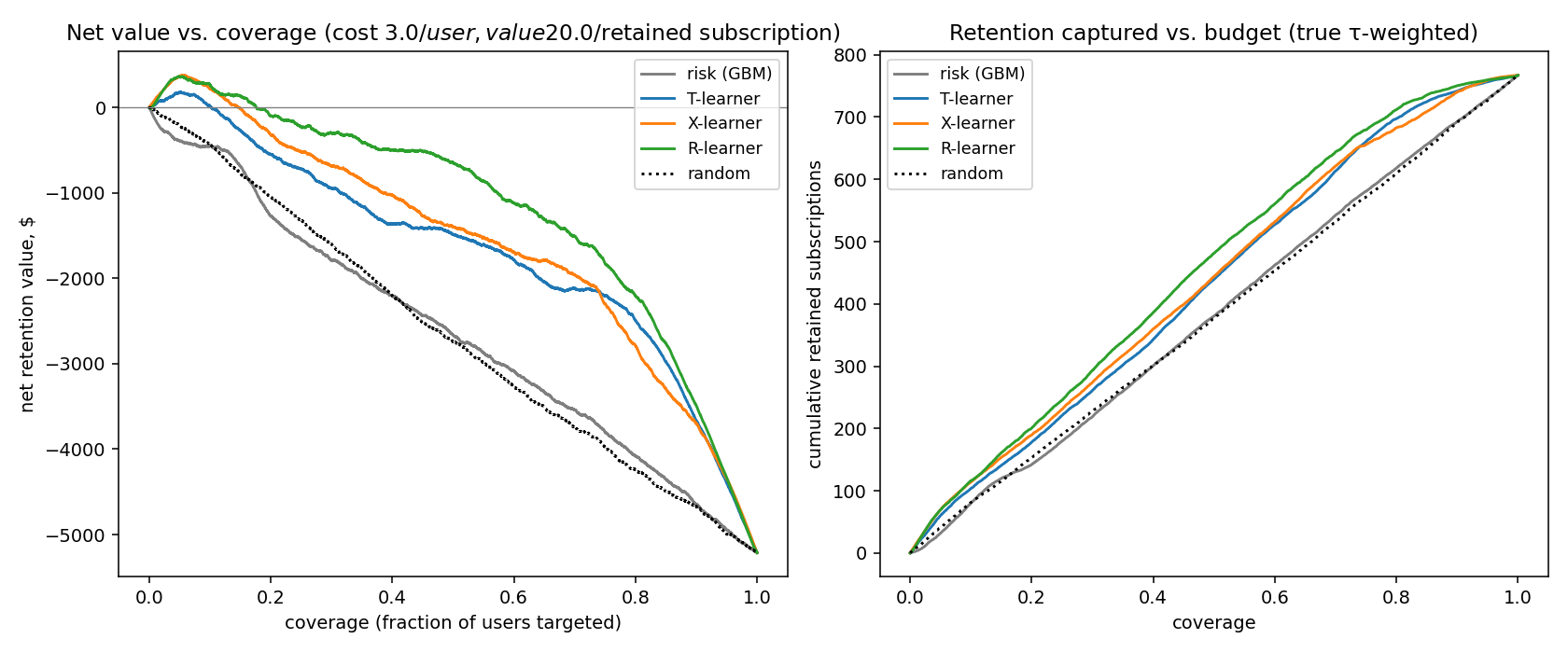
Subscription Churn Prediction & Causal Uplift Modeling
KKBox subscription churn pipeline (real Kaggle data, 6.8M members) — LightGBM at ROC AUC 0.866, then a causal uplift model that retains +92% more value than risk-targeting on the same budget. Engagement-decay naive estimate flips sign under adjustment.
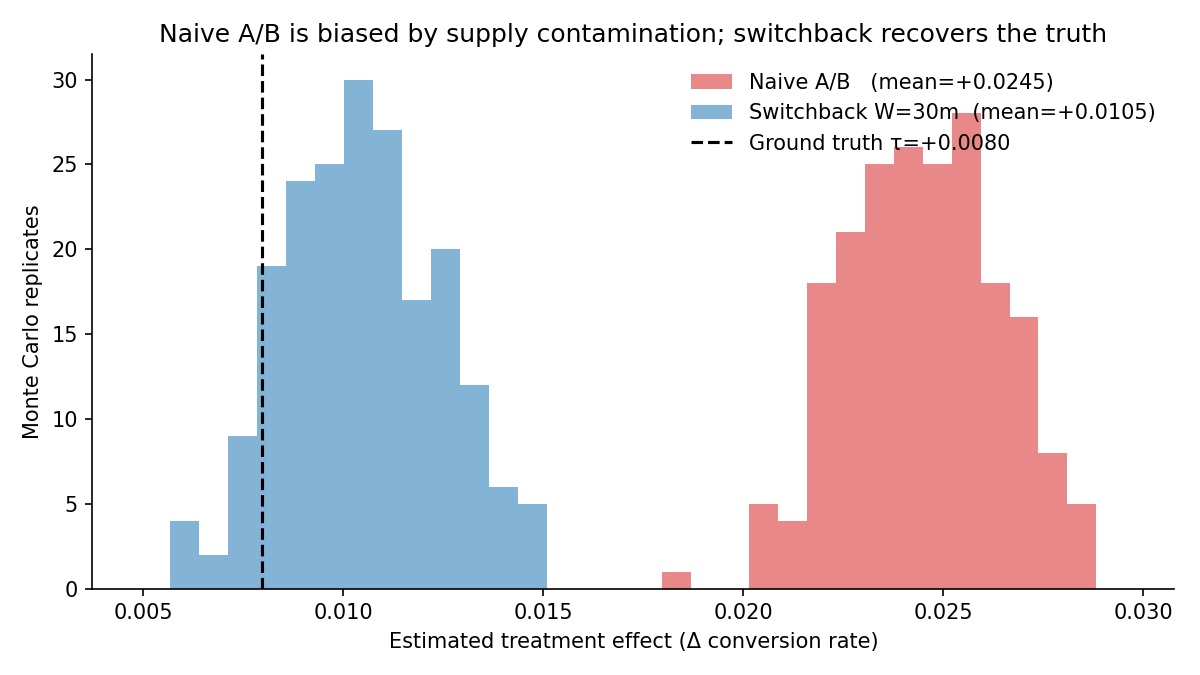
Switchback Experiments on a Simulated Marketplace
Built a two-sided rideshare marketplace, broke per-rider A/B testing on it (208% biased), and recovered the true effect with a switchback design. Worked-through bias-variance tradeoff in window length, cluster-robust SEs, and a power analysis that explains why marketplaces need 6–8 week experiments.
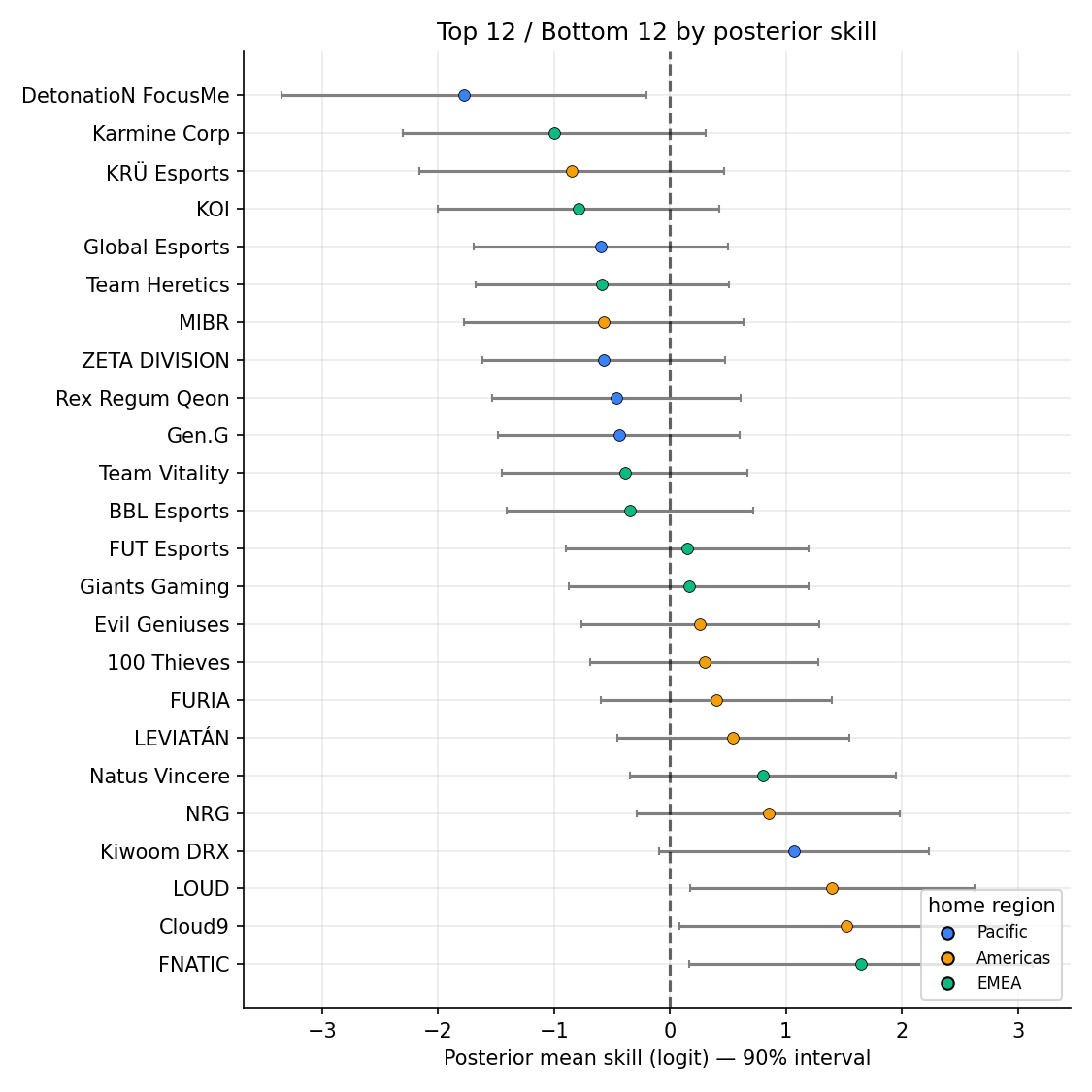
Hierarchical Bayesian Skill Rating for Pro Valorant
Hierarchical Bradley–Terry with map, region, and time pooling. On 86 held-out cross-regional matches, log loss 0.600 vs Elo's 0.640 (95% CI [−0.019, +0.098]); ECE drops 0.092 → 0.060 and confident calls (≥70%) land at 78% empirical.

Pickleball Vision: CV-Driven Match Analytics
A computer-vision pipeline that turns a fixed-camera pickleball clip into an annotated video with player tracking, ball tracking, court geometry, top-down minimap, and per-frame analytics — ball speed, player speed/distance, shot count. YOLOv8 + a fine-tuned ResNet50 court keypoint regressor + iterative homography refinement.
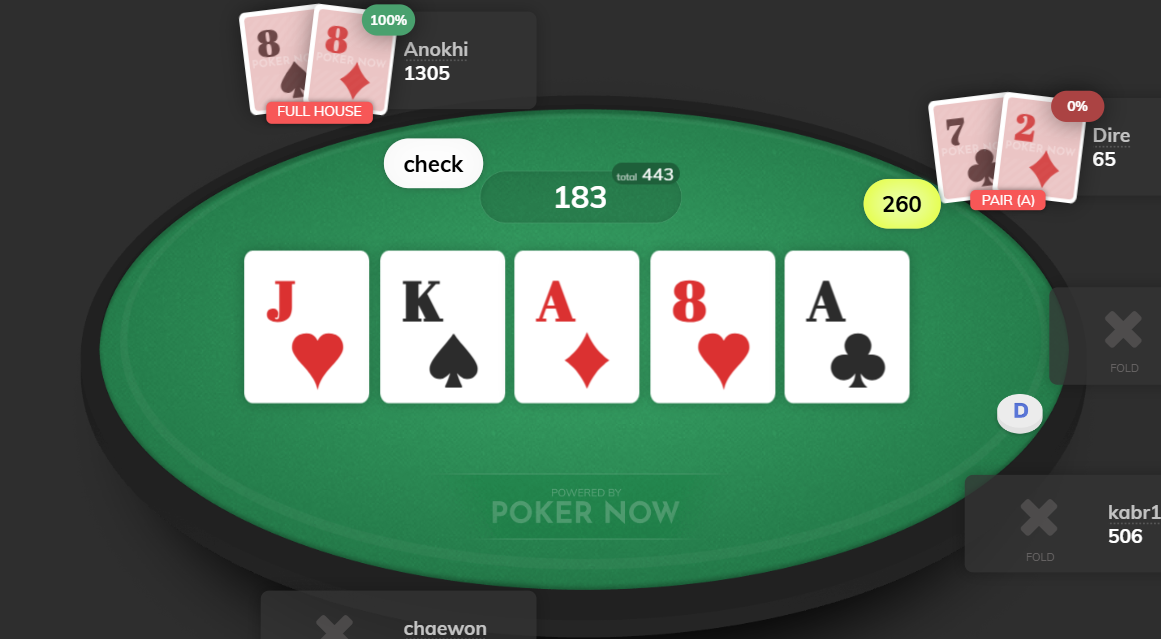
LSTM-Driven Poker Analytics & Bluff Prediction Platform
Developed an end-to-end machine learning pipeline that extracts, cleans, and feature-engineers over 5.7k real-money hand histories from PokerNow.club. Leveraging advanced feature engineering (bet ratios, decision times, board evaluations with Ace detection, and dynamic positional metrics) and a custom LSTM model with dynamic bucketing, the system predicts bluff versus value betting with a test AUC of 0.77. Hyperparameter tuning, cross-validation, and class balancing were key to optimizing performance.
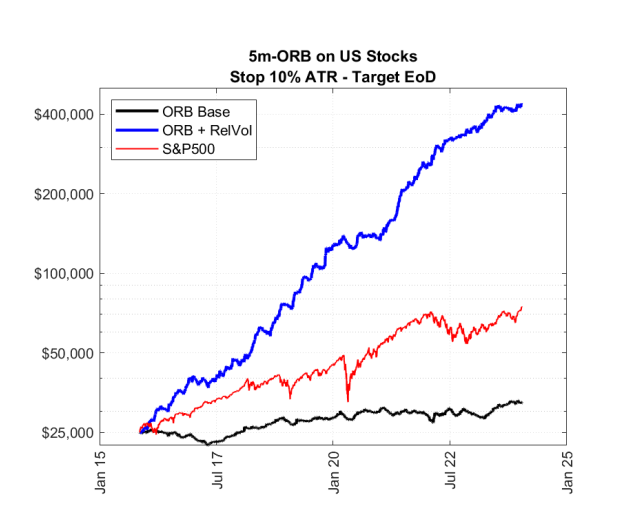
ORB Algorithmic Day-Trading System
Opening-Range-Breakout strategy on TQQQ with an XGBoost gating layer that decides whether to take the day's signal at all. SQL-driven feature pipeline, multi-interval simulation, and a +19.1% annualized return improvement over the unfiltered ORB baseline.