LSTM-Driven Poker Analytics & Bluff Prediction Platform
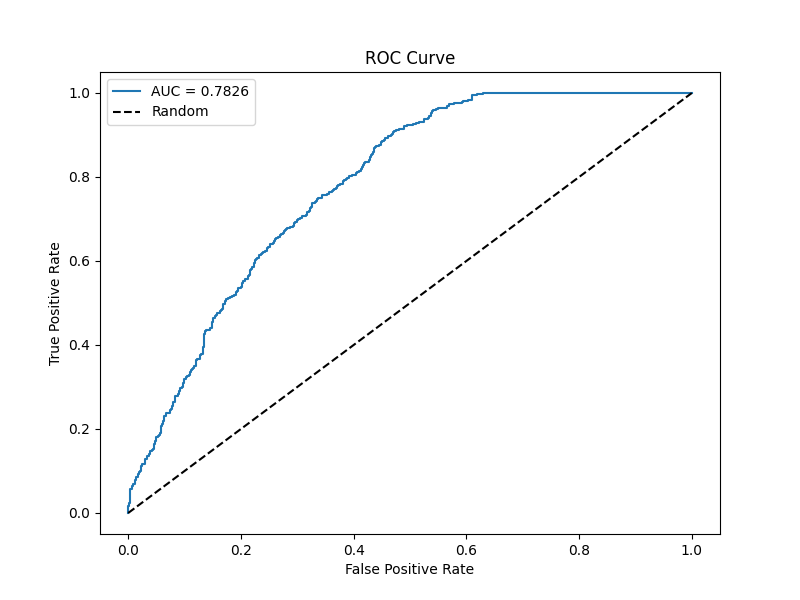
Developed an end-to-end machine learning pipeline that extracts, cleans, and feature-engineers over 5.7k real-money hand histories from PokerNow.club. Leveraging advanced feature engineering (bet ratios, decision times, board evaluations with Ace detection, and dynamic positional metrics) and a custom LSTM model with dynamic bucketing, the system predicts bluff versus value betting with a test AUC of 0.77. Hyperparameter tuning, cross-validation, and class balancing were key to optimizing performance.
When someone fires a big bet in poker, they’re either bluffing or value-betting. Telling the difference is the game. Skilled players read timing, bet sizing, board texture, and opponent history; this project asks whether an LSTM can do it on the same information.
I scraped 7,000+ real-money hands from PokerNow.club (blinds $0.25/$0.50 to $2/$5), engineered features around bet ratios, log-transformed decision times, board texture (paired, flush-draw, Ace-on-board), and positional context, then trained an LSTM with dynamic bucketing to predict, at the moment a big bet is made, whether it’s a bluff or a value bet.
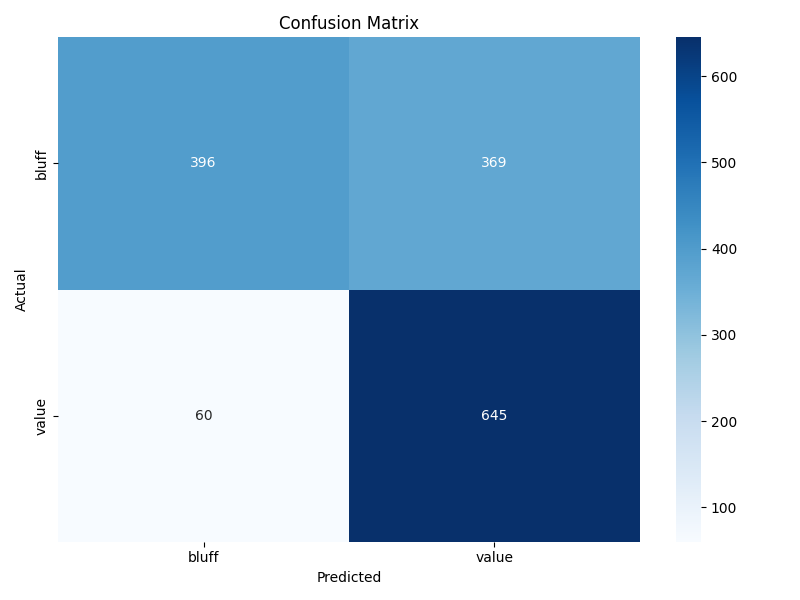
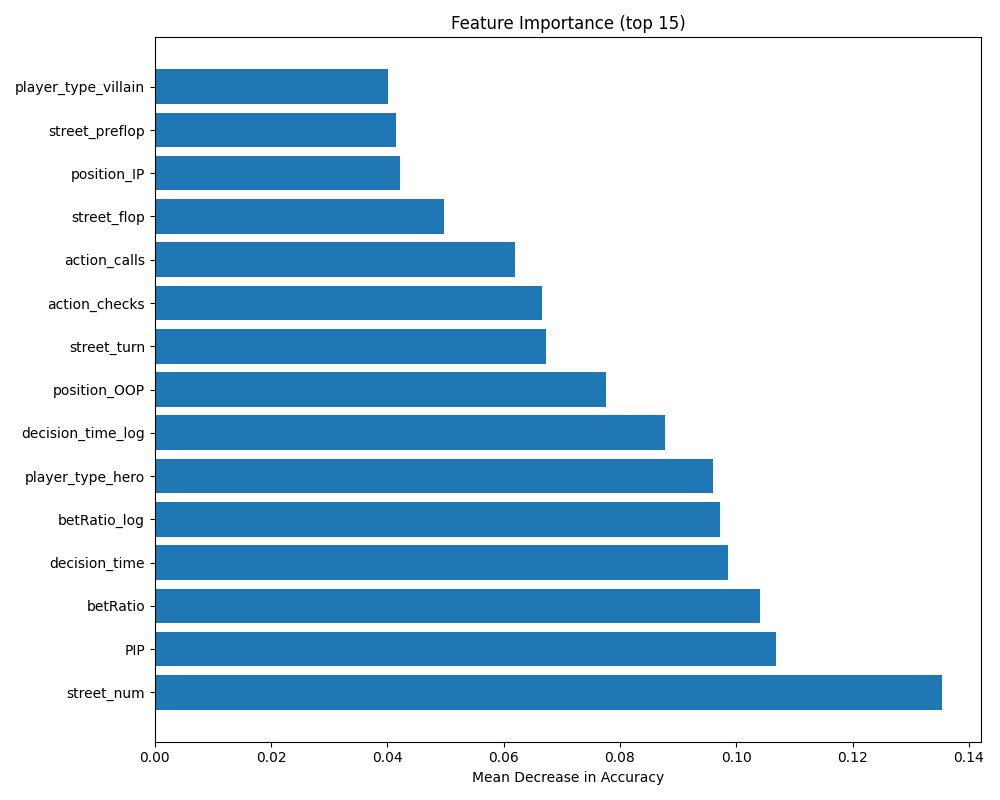
Final test AUC 0.77. The more interesting output is the feature-importance ranking, which gives a quantitative picture of what tells low-to-mid-stakes players are actually leaking.
Output
Below is a screenshot from the model evaluation dashboard displaying the confusion matrix, ROC curve, and feature importance chart:
Models & Techniques Used
- LSTM Network with Dynamic Bucketing: Processes variable-length sequences of poker actions.
- Bidirectional LSTM Layers: Capture context from both the past and future actions.
- Advanced Feature Engineering: Incorporates bet ratios, decision times (log-transformed), board evaluations (with Ace detection), and positional metrics.
- Cross-Validation & Class Balancing: Ensures robust model performance despite class imbalance (52% bluffs).
Training
- Data Preprocessing: Raw hand histories are cleansed, features are engineered, and sequences are built per hand. Numerical features are standardized and categorical features are one-hot encoded.
- LSTM Model Training: The model is trained using a combination of Bidirectional LSTMs, dropout, batch normalization, and L1/L2 regularization. Training is optimized via early stopping and learning rate reduction with cross-validation.
- Dynamic Bucketing: Instead of padding all sequences to a global maximum, hands are bucketed by similar sequence lengths to reduce wasted computation and improve training efficiency.
Requirements
- Python 3.8+
- TensorFlow 2.x
- Pandas, NumPy, Scikit-Learn
- Matplotlib, Seaborn (for visualization)