Deep CFR for 5-Card PLO Heads-Up
Stage 6 of a neural-CFR research arc — porting Deep CFR from HUNL to 5-card PLO heads-up. Composition-dependent encoder, opp-value board cache (99.4% hit rate, 58× steady-state encode speedup), equity-pretrained warm start, and an honest profile of why scaling the action grid is harder than scaling the cards.
In plain English
PLO stands for Pot-Limit Omaha, a poker variant similar to Texas Hold’em except each player gets four hole cards instead of two and must use exactly two of them combined with three from the board. 5-card PLO is the same thing but with five hole cards. It’s the most popular high-stakes cash game variant outside of no-limit Hold’em and is famously the most mathematically complex form of poker — there are far more possible hands and the equity calculations between hands are much closer, so the strategy involves much more nuance.
This project teaches a neural network to play heads-up 5-card PLO at near-equilibrium strength, using the same Deep CFR algorithm I built up to in the HUNL project (the no-limit Hold’em version). PLO5 has no published Deep CFR work — even Pluribus and Libratus stop at Hold’em — so this is original research-grade implementation, not a port of someone else’s code.
The headline isn’t a final exploitability number (the training is still running and won’t finish for weeks of compute). The headline is engineering: I diagnosed a 12–25× performance gap between what I had and what’s needed to finish in reasonable time, applied a series of optimizations that delivered a 58× speedup on the dominant cost, and then honestly reported that the encoder is no longer the bottleneck and the remaining work has to come from a different lever (multi-process traversal). It’s the kind of profile-driven optimization story that’s more useful than a glossy result, because it shows what scaling really looks like.
Why PLO5
Heads-up no-limit hold’em was solved (Stage 4). 4-card PLO is in the literature. 5-card PLO — five hole cards, choose-2 in your hand combined with choose-3 from the board — has no published Deep CFR work and adds two non-trivial complications over PLO4:
- Hand-evaluator combinatorics:
C(5,2) × C(5,3) = 100two-and-three combos per (hand, board) pair. The PLO5 evaluator (plo5_evaluator.py) computes all 100 and takes the best — this is not aphevaluatorcall, it’s its own thing. - Encoder cost: 5-card hands push state-feature dimensionality up, and naive equity computation per state explodes.
That second complication is what dominated Stage 6 engineering.
The encoder optimization that mattered
In the K=500 smoke profile, the original encoder ran at 2,620 µs / encode. A K=10,000 traversal at 300 iters would have taken 100 days. So I rebuilt the hot path:
- Opp-value cache keyed by canonical board → distribution over opponent ranges; populated lazily, persists across the iter
- Numpy vectorization of the per-combo equity rollouts
- Classify memoization of board-class lookups (flush / straight / paired structures)
K=500 diagnostic results, post-optimization:
| µs / encode | cache hits / misses | |
|---|---|---|
| Cold cache (warm-up pass) | 79.0 | 525 / 367 |
| Warm cache (steady state) | 44.8 | 892 / 0 |
| Pre-optimization baseline | 2,620 | n/a |
58× steady-state encoder speedup, 99.39% opp-value cache hit rate across a 1.46M-decision-point traverse, GPU forwards down to 0.8% of traverse wall. Cache works.
The honest readout: encoder is no longer the bottleneck
After the optimization, a single K=500 traverse pass took 703.7 s for 1,461,675 decision points = 481 µs / query. Of that, the encoder is ~45 µs (warm). The other ~436 µs / state is Python overhead in the traversal loop itself:
- generator
yield/send/stack save-restore across a 2.3M-call hot path - frozen-dataclass
PLO5Statereconstruction inapply_action legal_action_maskrecomputation- reservoir-buffer writes for traverser nodes
- numpy mask/sigma allocations in the inner loop
GPU is essentially idle during traversal (0.8% of wall in forwards). Adding bigger nets or larger batches would barely move iter wall.
Component-level iter budget at K=500
| component | wall | % |
|---|---|---|
| traverse × 2 players | 1,407.4 s | 98.0% |
| aux rollouts × 2,000 | 1.5 s | 0.1% |
| V rollouts × 2,000 | 1.4 s | 0.1% |
| train R × 800 (× 2) | 9.6 s | 0.7% |
| train S × 1,000 (× 2) | 11.8 s | 0.8% |
| train V × 500 (× 2) | 3.2 s | 0.2% |
| TOTAL | 23.9 min/iter | 100% |
Extrapolated to K=10,000 × 300 iters: ~100 days vs. the 4–8 day target. 12–25× too slow. The encoder lever is exhausted.
The remaining levers, ranked
| Approach | Speedup | Cost | Risk |
|---|---|---|---|
| (A) Multi-process traversal (8 workers) | 6–8× | 1–2 days; needs IPC for state batching | Memory amplification; pickling cost |
| (B) Reduce K from 10k → 2k | 5× | trivial | Slower convergence per iter |
| (C) Reduce action grid 10 → 5–6 slots | 2–3× | small game/encoder change | Loses pot-fraction granularity |
| (D) Iterative explicit-stack traversal | 1.5–2× | half-day refactor | Code complexity |
The current direction is (A) + (B) in tandem: 8-worker MP traversal at K=2,000.
Equity pretraining for warm starts
Stage 6d also pretrains the V/aux head on a 50k-state equity dataset (stage6d_equity_dataset.npz) generated by Monte-Carlo rollouts on canonical (hand, board) pairs. The pretrained checkpoint (stage6d_equity_pretrained.pt) lets the v3 ensemble start with non-random equity priors instead of bootstrapping them in the first 20 iters. The “BB60” variant in the v3 logs is this pretrained-init run.
Reference benchmark — Kuhn poker exploitability
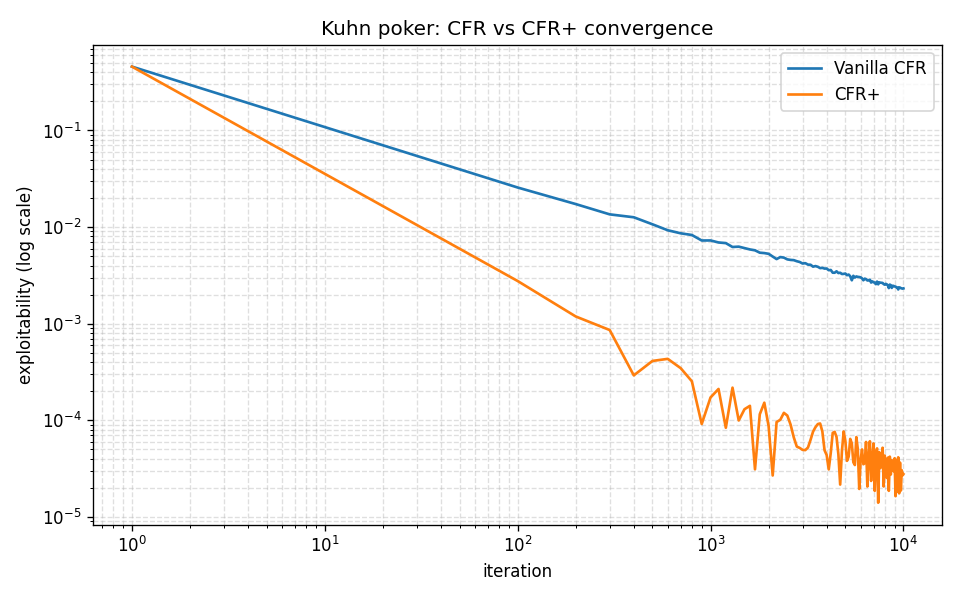
Stage 0 sanity check from the bottom of the arc: the tabular CFR+ implementation reproduces the published Kuhn equilibrium exactly. Every later stage’s pipeline is built on this foundation; if the floor is wrong, the ceiling is decoration.
What it demonstrates
- Engineering a research project that can’t fit in RAM or wall-time at the obvious settings, and re-architecting until it does
- Profile-first optimization: not “I optimized the encoder” but “here’s the 58× the cache buys, here’s the 9% of iter wall that’s left, here’s why we now need MP”
- Knowing when to stop optimizing one lever and switch to another
- Custom evaluator for a game with no off-the-shelf solver
- Equity pretraining as a warm-start technique for neural CFR